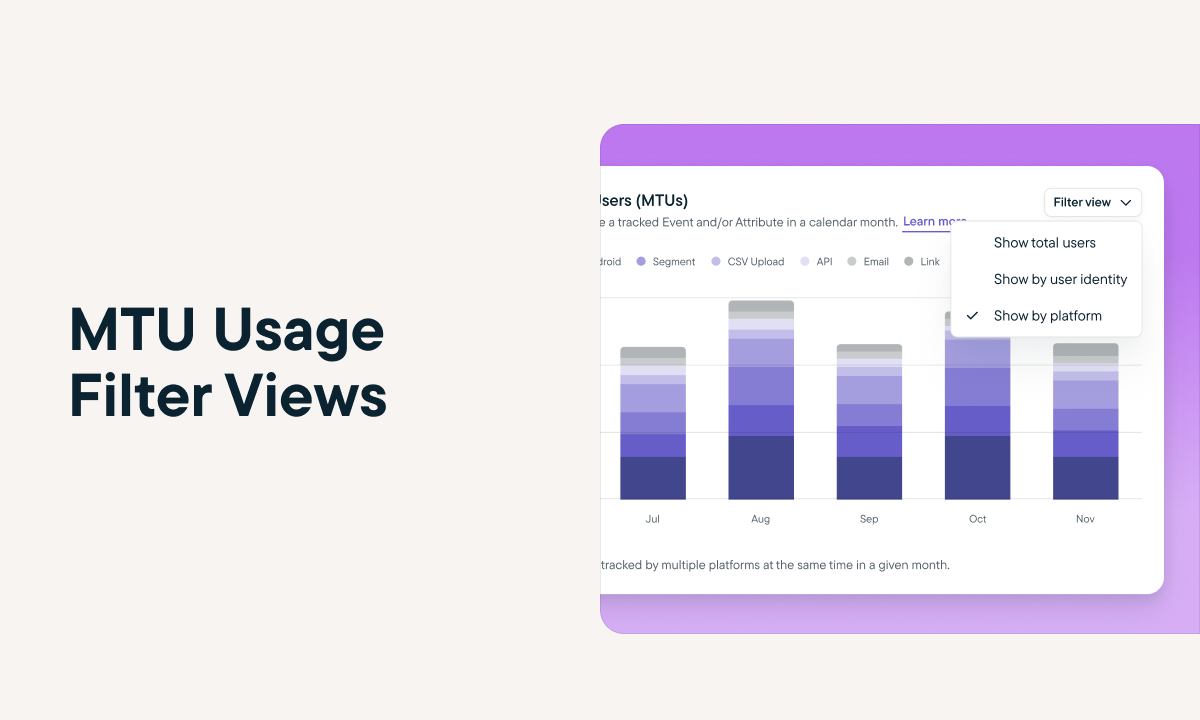
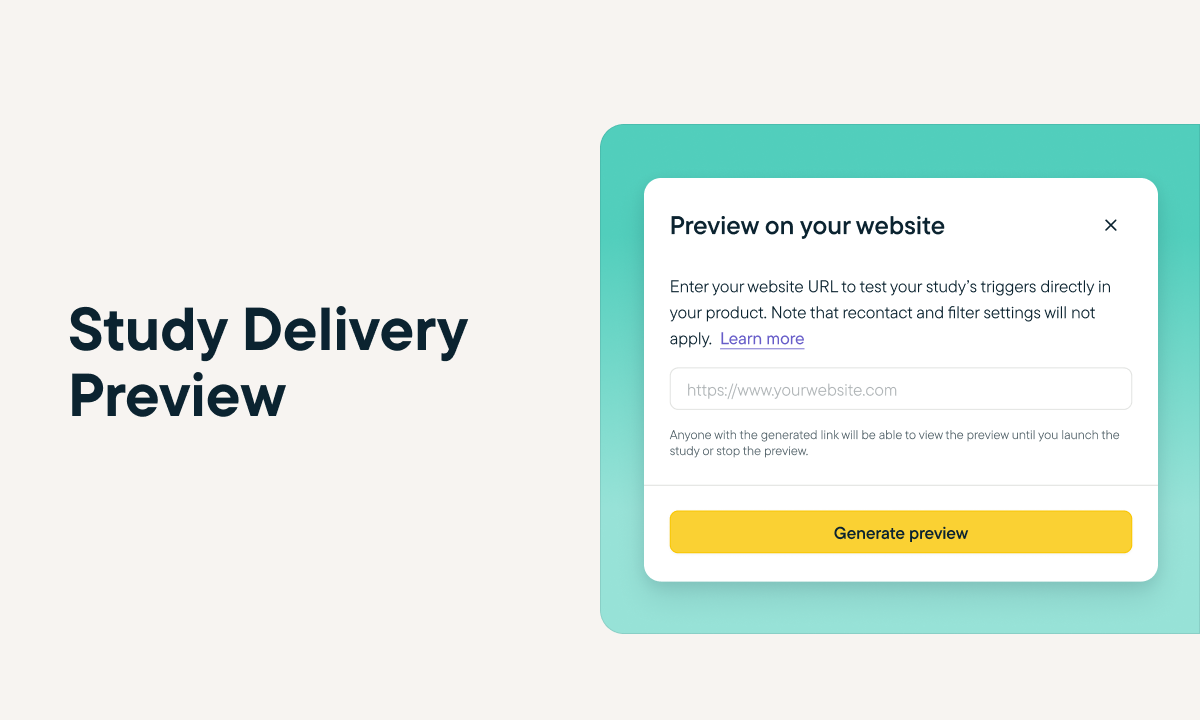
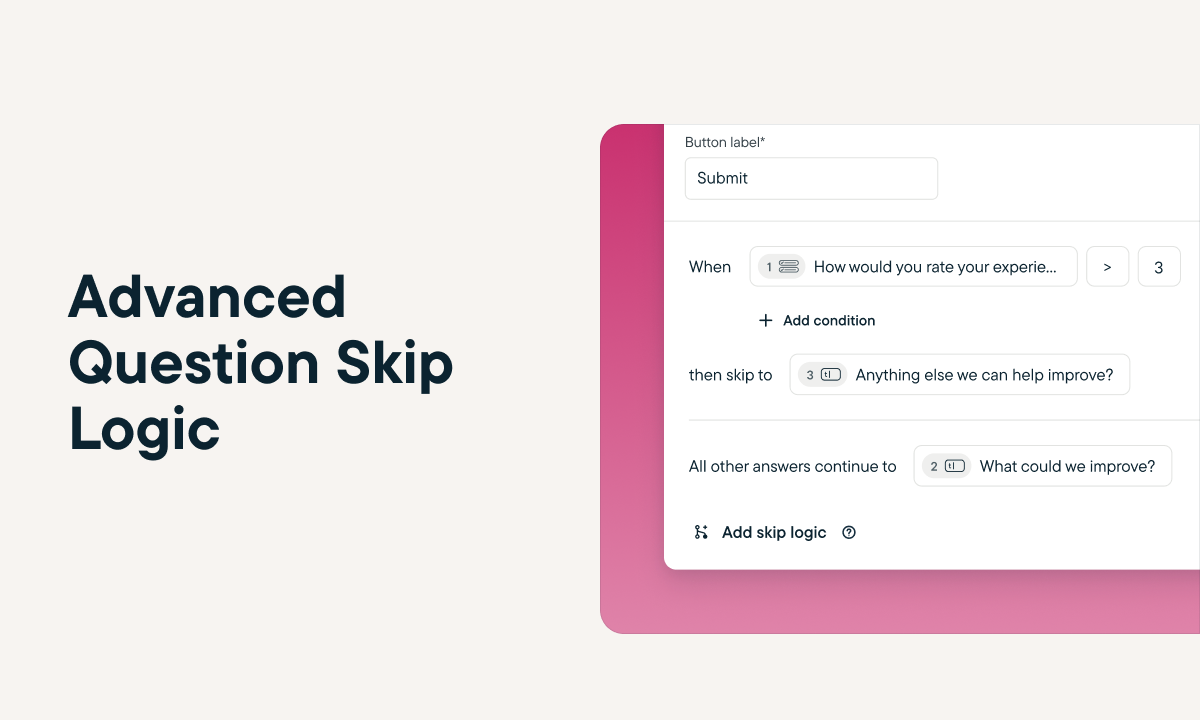
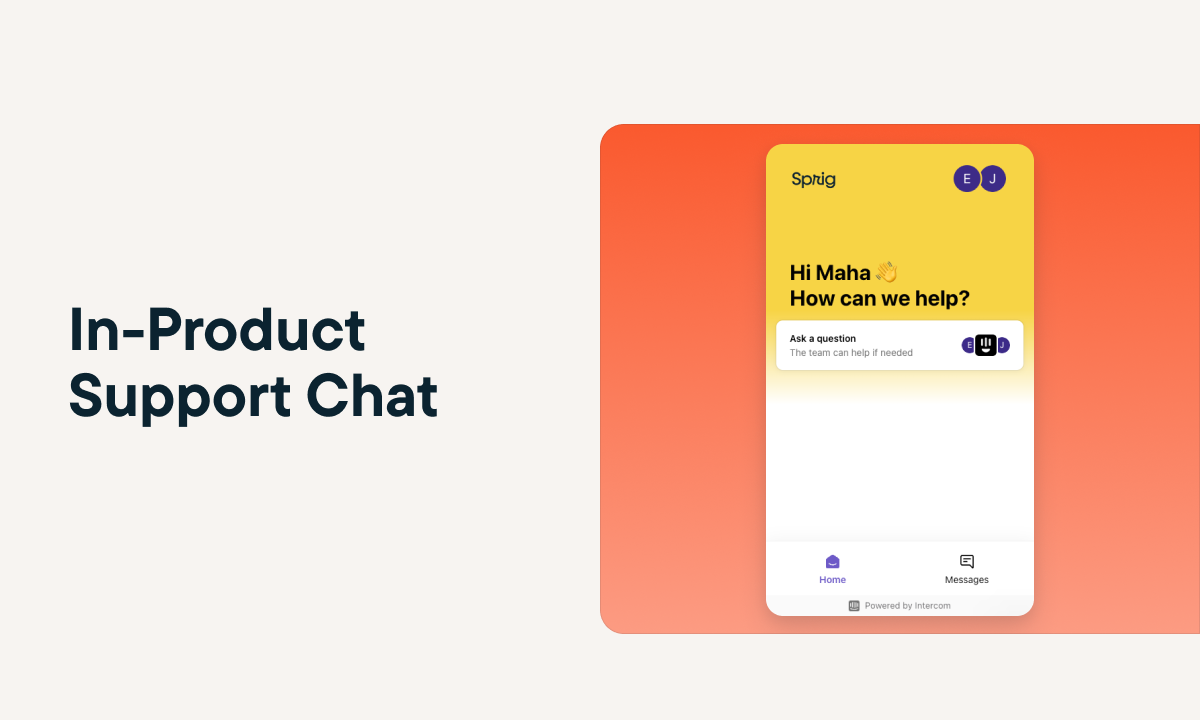
Sprig Replays is now available to all users!
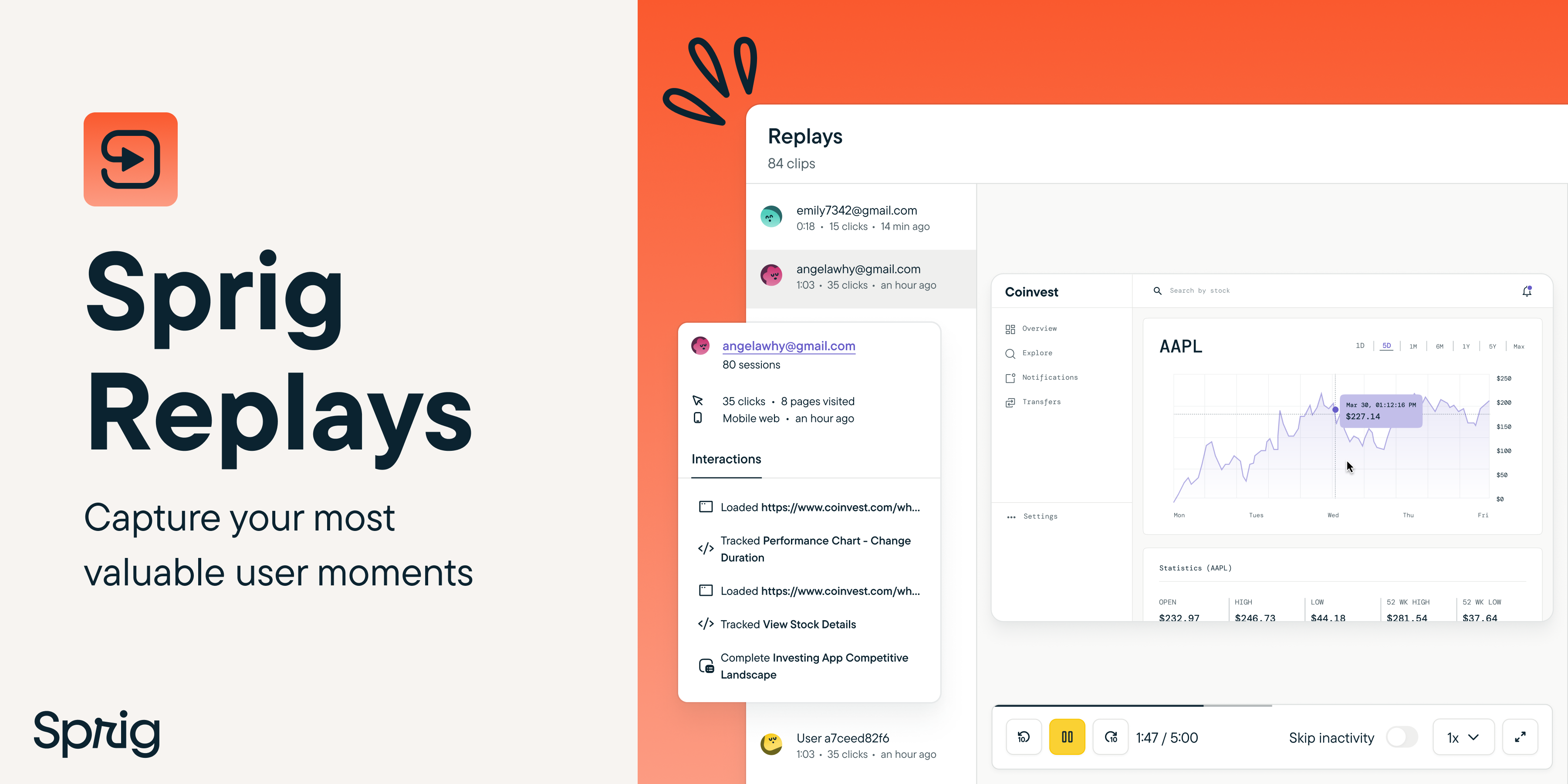
by Maha ChaudhrySprig Replays is now officially out of beta and available to all of our valued Sprig users across our Free, Starter, and Enterprise plans! With Replays, you can watch targeted clips of your product experience and pair them with in-product Surveys to connect the dots between users' sessions and sentiments. Here's why it’s a game-changer:
👀 Short, Focused Clips: Say goodbye to hours of watching recordings. Sprig Replays captures short clips of your users' product experiences, giving you a snapshot of their product behavior.
🚀 Targeted Insights: Pinpoint and capture the specific user moments that you’re interested in (like your onboarding flow or new feature engagement) with event-based targeting.
📊 Pair with Surveys: Take your insights up a notch by pairing Replays with in-product Surveys to understand exactly what experiences influence your users' sentiment and how you can enhance it.
To start using Sprig Replays, log in to your Sprig account, and you'll be able to explore this powerful new addition to our platform -- just make sure your team is on the latest Sprig SDK. Want some guidance to help you make the most of this product? Check out our Replays tutorial video and documentation.